日立、既存の物体検知AIを高精度に補正する新技術を開発
日立が物体検知AIの精度を大幅に向上させる新技術を発表
日立は、製造現場や社会インフラなど、さまざまな場所で使われている物体検知AIの性能を、さらに高める新しい技術を開発しました。この技術を使うと、既存のAIを新しく学び直させたり、プログラムを修正したりすることなく、検知結果をより正確にすることができます。
物体検知AIの課題と新技術の目的
工場での製品検査や設備の点検、道路や橋の監視、ドローンを使った空からの調査など、多くの場面で画像や映像から特定の物体を見つけ出すAIが活躍しています。これらのAIは、品質管理や安全確保のためにとても重要ですが、まだ見たことのない物体や、背景が複雑な場所、時間の経過で環境が変わるような状況では、間違って検知したり(誤検知)、見逃してしまったりする問題がありました。
これまでの方法では、画像全体の情報と、細かい部分ごとの情報の両方をうまく使って補正することが難しく、さらに、既存のAIを修正する必要がある場合もありました。そこで、日立は、既存のAIをそのまま使いながら、さまざまなAIに後から適用できる、誤検知を減らし、見逃しをなくす技術を求められていました。
開発された技術の特長
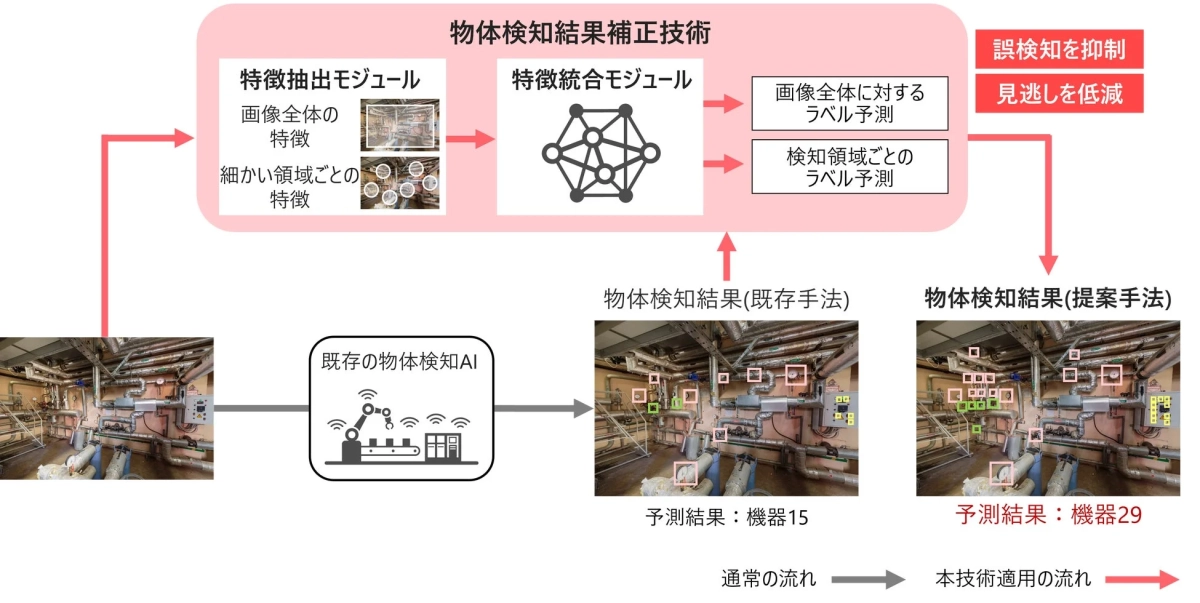
日立が開発したこの新しいAI技術は、既存の物体検知AIが出力した結果を利用し、画像全体と細かい領域ごとの情報をまとめて分析することで、検知結果を非常に高い精度で補正します。
1. 誤検知を減らし、見逃しをなくす補正技術
この技術は、まず画像から重要な情報を取り出す「特徴抽出モジュール」を使って、画像全体の情報と、細かい部分ごとの情報を取り出します。次に、これらの情報を「特徴統合モジュール」という部分に入力し、全体と細かい部分の関係性を互いに分析させます。これにより、画像全体が何であるかを判断する予測と、検知された部分が何であるかを判断する予測の両方を出せるように学習させます。最後に、これらの予測結果を、元の物体検知AIの結果と組み合わせることで、検知結果をより正確に補正します。これにより、画像全体と個々の検知結果を同時に考慮した補正が可能となり、誤検知を減らし、見逃しをなくすことが両立できます。

2. さまざまなAIに後付けできる設計
この技術は、画像と物体検知AIが出力する結果(「これは何であるか」という情報と、「どこにあるか」という位置情報)だけを情報として使うため、AIの内部の仕組みや、すでに学習したデータに影響されません。そのため、AIを新しく学び直させたり、プログラムを修正したりすることなく、既存のAIに適用できます。これにより、プログラムが公開されている通常の物体検知AIだけでなく、内部にアクセスできない、いわゆる「ブラックボックス型AI」(例えば、生成AIサービスなど)にも後から適用できるため、今使っている画像認識システムをそのまま活用できます。
確認された効果
この技術をいくつかの有名なテストデータで試したところ、「Grounding DINO」や「LLMDet」といった最新の物体検知モデルでも、 consistently 精度が向上することが確認されました。元の物体検知モデルと比べて、最大で50%以上の検知精度が改善しました。さらに、この技術を追加しても、1枚の画像を処理するのにかかる時間は0.1秒程度と短く、精度が上がるだけでなく、効率も良いことがわかっています。これにより、まだ見たことのない物体や、複雑な環境でも安定して物体を検知できるようになり、さまざまな実際の現場で利用できると考えられます。
今後の展望
日立は、この技術をデジタルソリューション「Lumada 3.0」を支える重要な技術の一つとして位置づけ、製造、設備保守、インフラ監視、空撮画像解析など、幅広い分野で活用を進めていく予定です。既存の画像認識システムを使いながら検知精度を高めることで、現場の安全確保や業務効率化をサポートします。また、それぞれの業務環境や目的に合わせた技術の進化や、他のAI技術との連携にも取り組み、より信頼性の高い画像認識の仕組みを築くことを目指しています。これにより、社会のデジタル化を加速させ、安全で持続可能な社会の実現に貢献していきます。
この成果の一部は、2026年6月3日から7日に開催される国際会議「CVPR 2026」のFindings Trackで発表される予定です。