リコー、Google「Gemma 3 27B」ベースの高性能日本語LLMを開発 – オンプレミス導入に最適


株式会社リコーは、Googleが提供するオープンモデル「Gemma 3 27B」を基に、オンプレミス環境への導入に最適な高性能な日本語大規模言語モデル(LLM)を開発しました。
独自の技術で高性能を実現
このLLMは、リコー独自のモデルマージ技術を活用し、元のモデルから大幅な性能向上を果たしています。約1万5千件の指示チューニングデータで追加学習したInstructモデルから抽出したChat Vectorなど、複数のChat Vectorを独自技術で「Gemma 3 27B」に組み合わせています。
同規模のパラメータ数を持つLLMとの比較では、米OpenAIのオープンウェイトモデル「gpt-oss-20b」など、最先端の高性能モデルと同等の性能が確認されています。このモデルは、高い初期応答性を持ちながら、優れた執筆能力も兼ね備えているため、ビジネスでの利用に適しています。
さらに、モデルサイズは270億パラメータとコンパクトでありながら高性能を実現しており、PCサーバーなどでも構築が可能です。これにより、低コストでプライベートLLMを導入できるだけでなく、LLMの高い電力消費による環境負荷の課題に対しても、省エネルギー・環境負荷低減に貢献します。
エフサステクノロジーズとの連携で提供
このLLMは、お客様の要望に応じて個別に提供されます。また、2025年12月下旬からは、エフサステクノロジーズ株式会社が提供するオンプレミス環境向けの対話型生成AI基盤「Private AI Platform on PRIMERGY(Very Small モデル)」に、LLMの量子化モデルと生成AI開発プラットフォーム「Dify(ディフィ)」がプリインストールされた形で、リコージャパン株式会社から提供されます。
Difyを活用することで、お客様は自社の業種や業務に合わせた生成AIアプリケーションをプログラミングの知識なしで作成できます。さらに、リコージャパンが提供する「Dify支援サービス」によるサポートも受けられるため、AIの専門人材がいない企業でも安心して生成AIの業務活用を始められます。
エフサステクノロジーズ株式会社の代表取締役社長 CEO 保田 益男氏は、リコーが開発した高性能LLMと自社のAI基盤を組み合わせたオンプレミスAIソリューションを、より多くのお客様に提供できることを歓迎するコメントを発表しています。
株式会社リコー リコーデジタルサービスBU AIサービス事業本部 本部長 梅津 良昭氏も、Googleの基盤モデルとエフサステクノロジーズの迅速な製品化により、多くの顧客の課題解決に貢献できると述べています。
評価結果
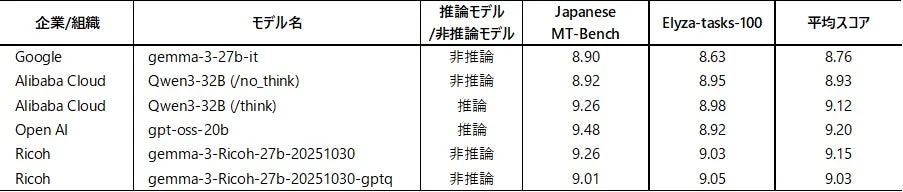
複雑な指示やタスクを含む日本語ベンチマーク「ELYZA-tasks-100」と、日本語のマルチターン対話能力を評価する「Japanese MT-Bench」を用いた性能評価では、リコーが開発したLLMは、米OpenAIの「gpt-oss-20b」をはじめとする高性能モデルと同等レベルの高いスコアを示しました。
各ベンチマーク・データセットの概要
-
Japanese MT-Bench: マルチターン対話設定のデータセットで、コーディング、抽出、人文、数学、推論、ロールプレイ、STEM、ライティングなどのタスクで構成されます。スコアは1(最低)から10(最高)の範囲です。
-
Elyza-tasks-100: 複雑な指示・タスクを含むデータセットで、要約の修正、意図の汲み取り、複雑な計算、対話生成など広範なタスクで構成されます。スコアは1(最低)から5(最高)の範囲です。比較のため、ここではスコアを2倍にして平均スコアを算出しています。
今後の展望とリコーのAI開発
リコーは今後、推論性能の向上や業種に特化したモデルの開発を進めるとともに、同社が強みとするマルチモーダル性能と合わせて、LLMのラインアップをさらに強化していく予定です。
リコーは1980年代からAI開発に着手し、2015年からは画像認識技術を活用した深層学習AI、2021年からは自然言語処理技術を用いた「仕事のAI」を提供してきました。2022年からはLLMの研究・開発にも取り組み、お客様のニーズに応じたAI基盤開発を進めています。独自のモデルマージ技術などを活用し、お客様の用途や環境に最適なプライベートLLMを低コスト・短納期で提供しています。画像認識、自然言語処理に加え、音声認識AIの研究開発も推進し、音声対話機能を備えたAIエージェントの提供も開始しています。
リコーは、お客様に寄り添い、業種業務に合わせて利用できるAIサービスの提供により、オフィスや現場のデジタルトランスフォーメーション(DX)を支援していくとしています。
関連リンク
-
Google Gemma 3 27Bについて: https://ai.google.dev/gemma/docs/core?hl=ja
-
OpenAI gpt-oss-20bについて: https://openai.com/ja-JP/index/introducing-gpt-oss/
-
リコーのAI開発について: https://promo.digital.ricoh.com/ai/